
Choosing a large language model in 2025–2026 means weighing raw performance, cost per token, speed, context length, and whether you need open weights or proprietary APIs. This post uses a dataset of 24 leading models (LLM Benchmark Wars 2025–2026 | 24 Models Compared, Kaggle, alitaqishah) to answer: who leads on overall and per-benchmark scores, which models offer the best value for money, how speed and quality trade off, and how open-source and proprietary stacks compare. We combine rankings, benchmark breakdowns, pricing and efficiency metrics, and release timelines into a single data-backed view of the current landscape.
![]()
The leaderboard
In the dataset, models are ranked by a composite overall benchmark average across MMLU, HumanEval, GPQA Diamond, SWE-bench, HellaSwag, and AIME 2025. The spread is wide: from about 48 at the bottom to 90.3 at the top.
Top five by overall benchmark average
- GPT-5.2 (OpenAI) — 90.3
- Gemini 3.1 Pro (Google DeepMind) — 90.22
- Claude Opus 4.6 (Anthropic) — 89.6
- Claude Opus 4.5 (Anthropic) — 88.82
- GPT-5.3 Codex (OpenAI) — 88.62
GPT-5.2 and Gemini 3.1 Pro are effectively tied at the top; the Claude Opus line and GPT-5.3 Codex fill the next slots. So the frontier is currently a narrow band of proprietary, mostly multimodal models from OpenAI, Google, and Anthropic. Below that, Qwen3.5 Plus, Grok 4.1, Gemini 2.5 Pro, and Claude Sonnet 4.6 round out a strong top 10, with a mix of proprietary and open-weight offerings.
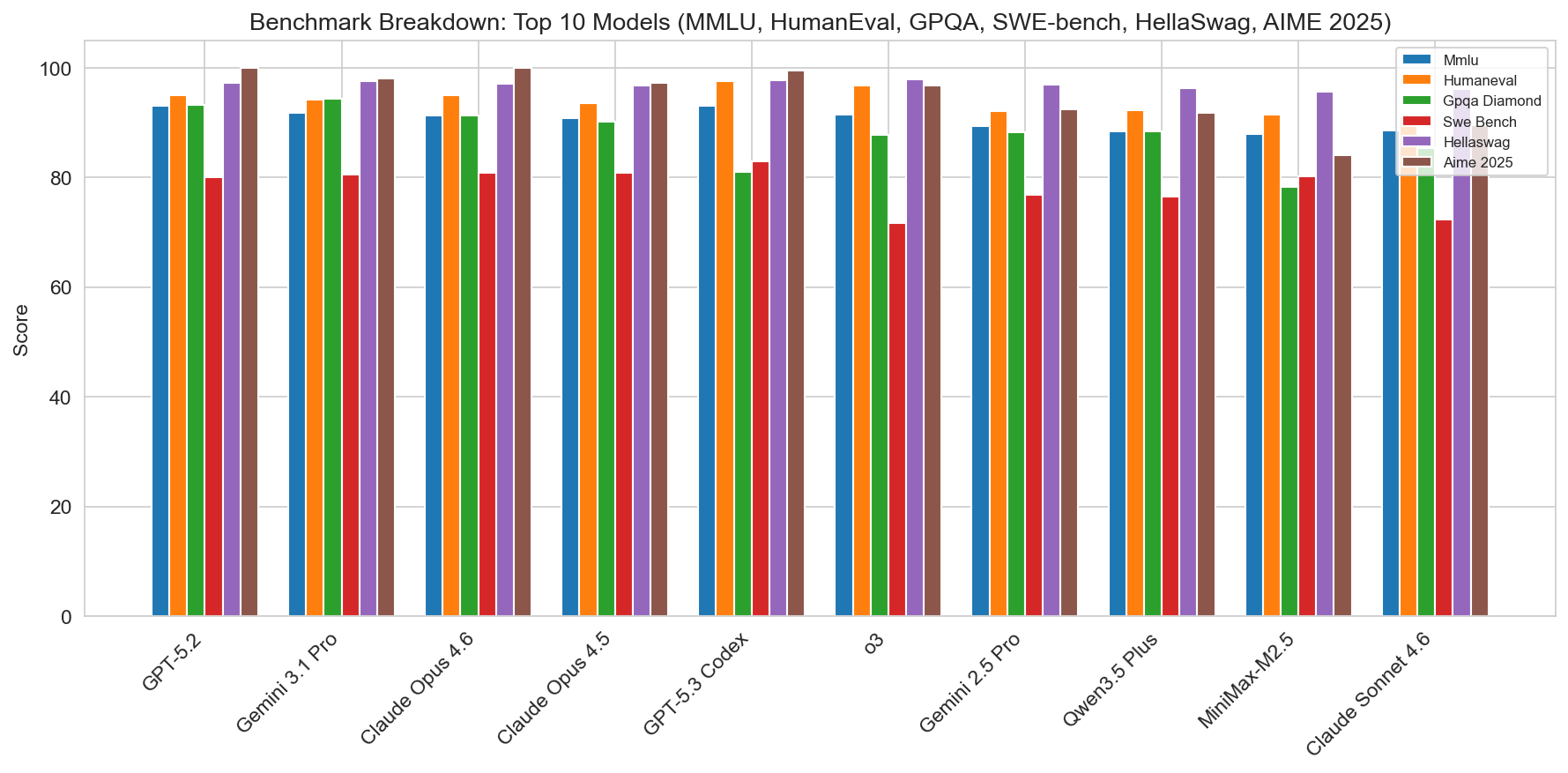
Benchmarks that matter
The dataset aggregates six benchmarks, each stressing different capabilities.
- MMLU (Massive Multitask Language Understanding): broad knowledge across many subjects.
- HumanEval: code generation (Python).
- GPQA Diamond: difficult multiple-choice questions (science, etc.).
- SWE-bench: real-world software engineering tasks (resolving GitHub issues).
- HellaSwag: commonsense reasoning / sentence completion.
- AIME 2025: competition-style math (American Invitational Mathematics Examination).
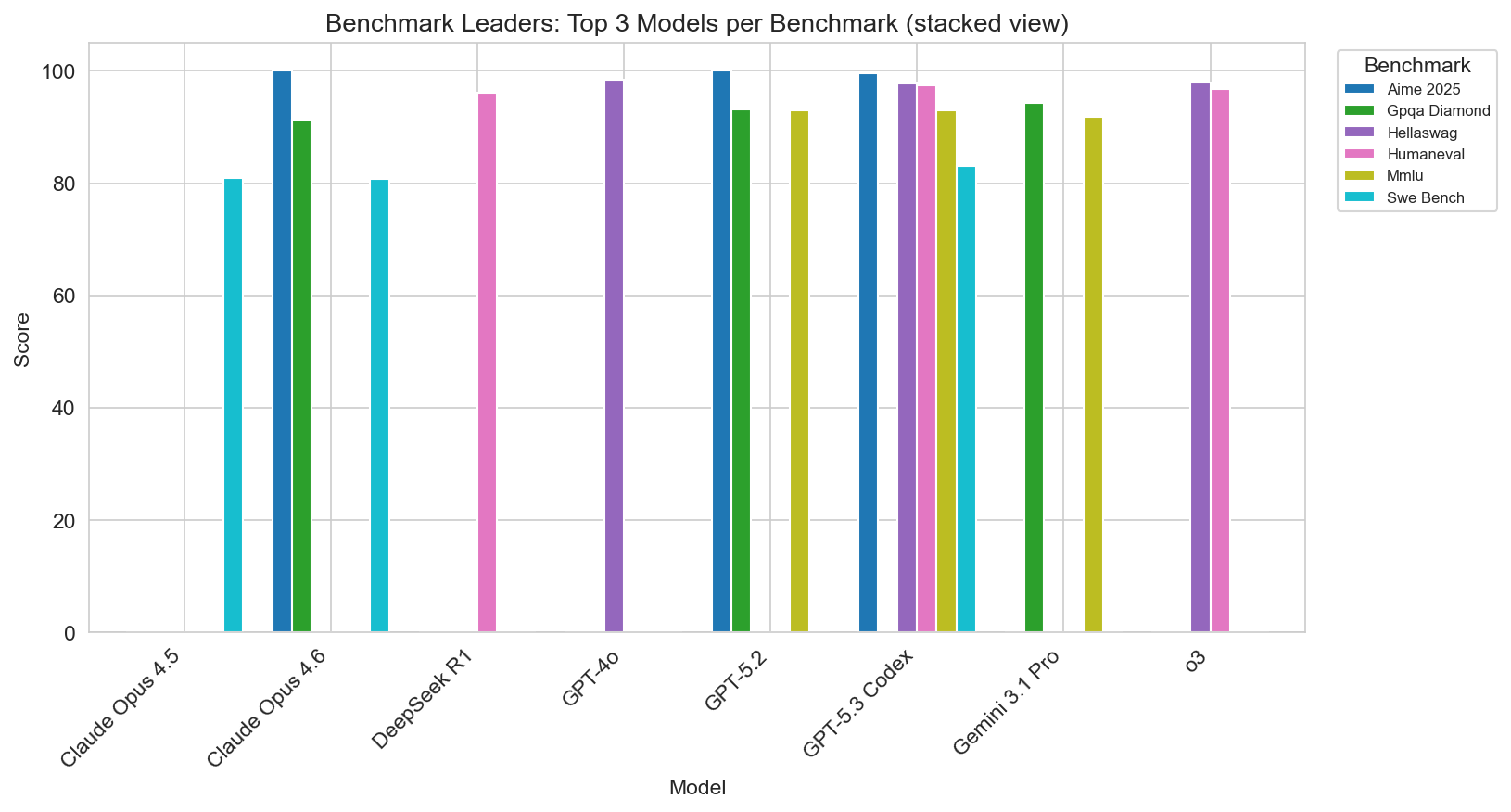
Who leads each benchmark (single leader in this set)
- MMLU: GPT-5.2 (93.0)
- HumanEval: GPT-5.3 Codex (97.5)
- GPQA Diamond: Gemini 3.1 Pro (94.3)
- SWE-bench: GPT-5.3 Codex (83.0)
- HellaSwag: GPT-4o (98.4)
- AIME 2025: GPT-5.2 (100.0)
So OpenAI and Google share the top spots across benchmarks: GPT-5.2 leads on MMLU and AIME, GPT-5.3 Codex on HumanEval and SWE-bench, Gemini 3.1 Pro on GPQA, and the older GPT-4o still leads HellaSwag. If your workload is code-heavy, Codex and Claude Opus are strong; for long-context and multimodal, Gemini 3.1 Pro and Claude stand out; for math and broad knowledge, GPT-5.2 is at the front.
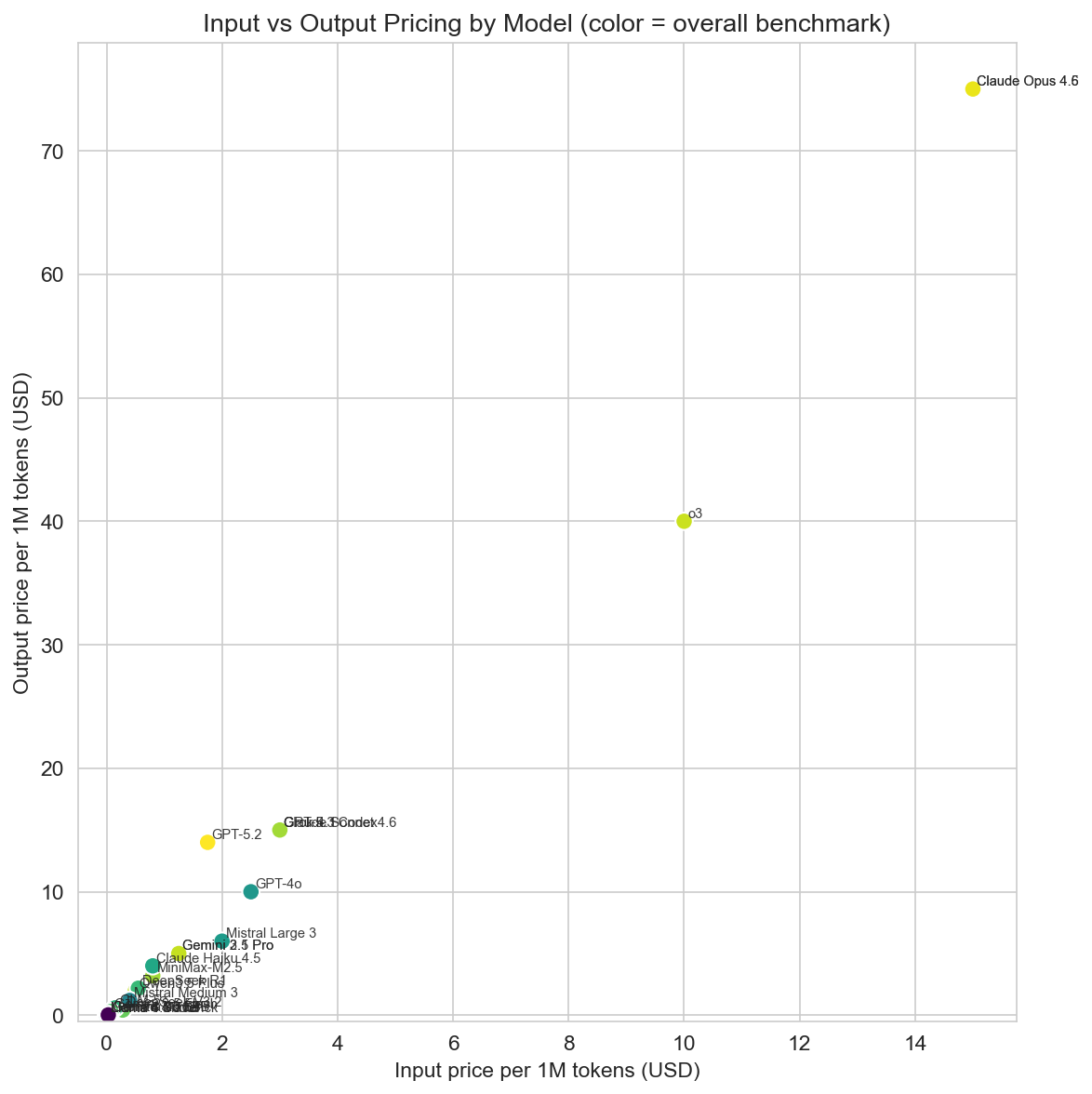
Cost and value
Pricing in the dataset is given as input and output price per 1M tokens (USD). There is a huge range: from $0 (Llama 4, Llama 3.3, self-hosted / free tier) to $15 input and $75 output for Claude Opus. Mid-range APIs (e.g. GPT-5.2, Gemini 3.1 Pro) sit in the $1–4 per 1M input band; budget options (DeepSeek, Qwen, GLM-5, Gemini 2.5 Flash) go down to $0.075–0.5 input.
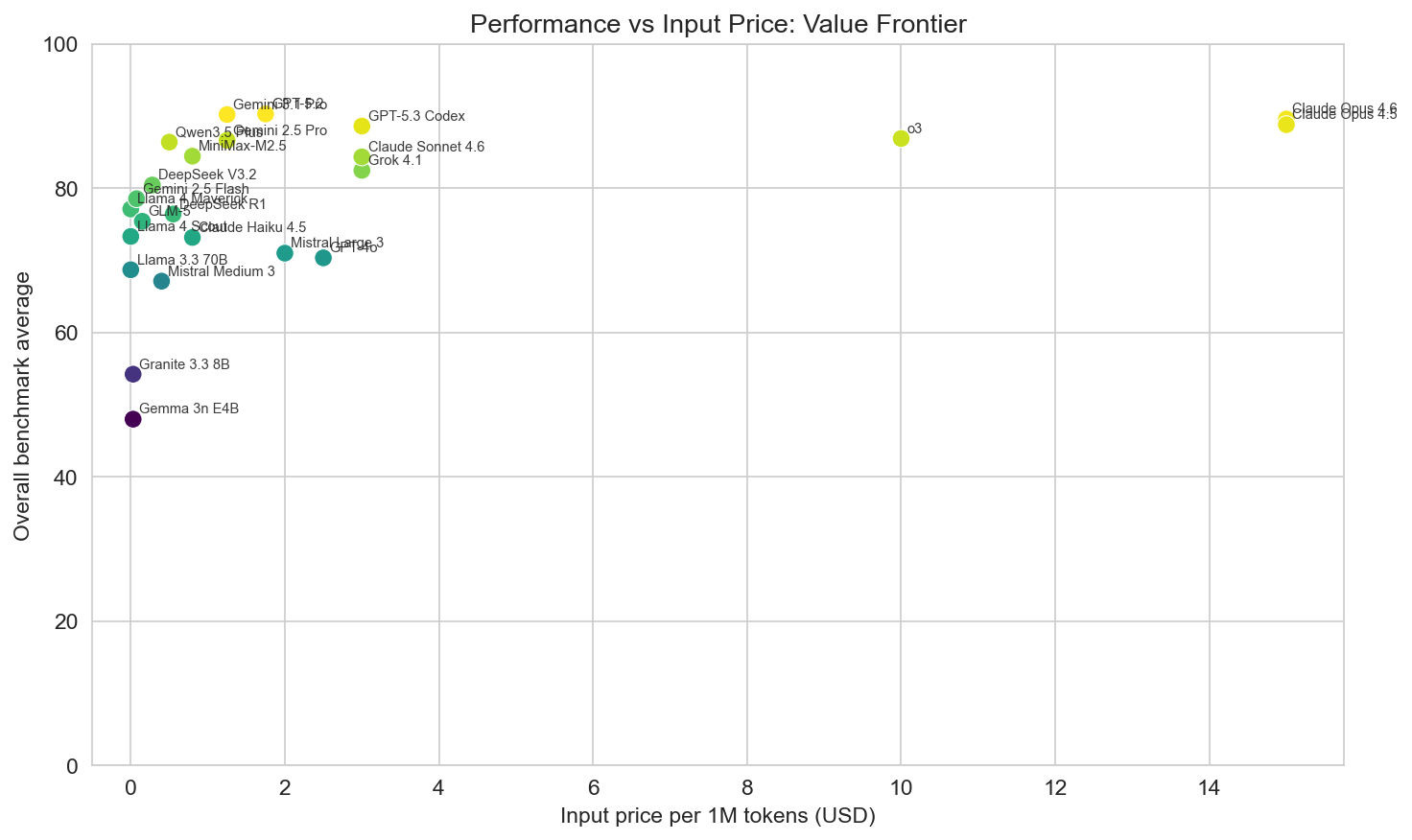
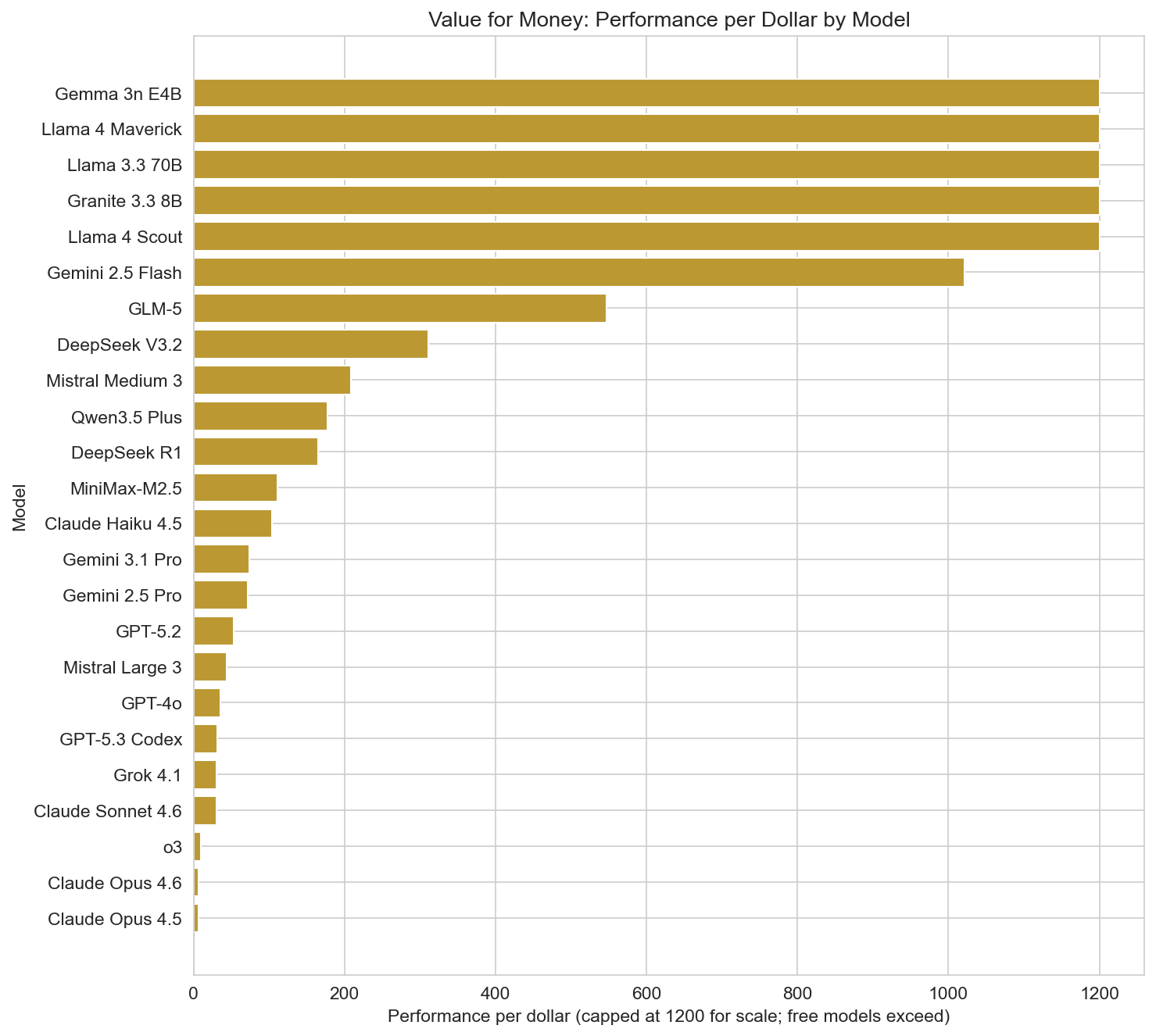
Value for money can be approximated by performance per dollar: overall benchmark average per unit cost. Free or near-free models dominate this metric by construction: Llama 4 Maverick, Llama 4 Scout, and Llama 3.3 70B show the highest performance-per-dollar in the dataset (with values in the thousands when cost is near zero). Among paid APIs, DeepSeek V3.2 (310.86), Qwen3.5 Plus (177.16), DeepSeek R1 (165.18), and Gemini 3.1 Pro (73.81) are strong value options—high scores at relatively low cost. Claude Opus and GPT-5.3 Codex sit at the premium end: top quality but low performance-per-dollar, so they are best when raw capability matters more than cost.
Speed and latency
Speed is reported as tokens per second; latency as seconds (e.g. time to first token or similar). The fastest models in the set are Gemini 2.5 Flash (347 tok/s), Granite 3.3 8B (387 tok/s), GPT-4o (232 tok/s), and Claude Haiku 4.5 (185 tok/s). These are either small open models (Granite, Gemma) or optimized “flash”/“haiku” tiers. The highest-scoring models (GPT-5.2, Gemini 3.1 Pro, Claude Opus) are in the 60–120 tok/s range—fast enough for many apps but not “ultra-fast.” Reasoning models (e.g. o3, DeepSeek R1) are slower and have higher latency, which fits their use case: complex chains of thought rather than real-time chat.
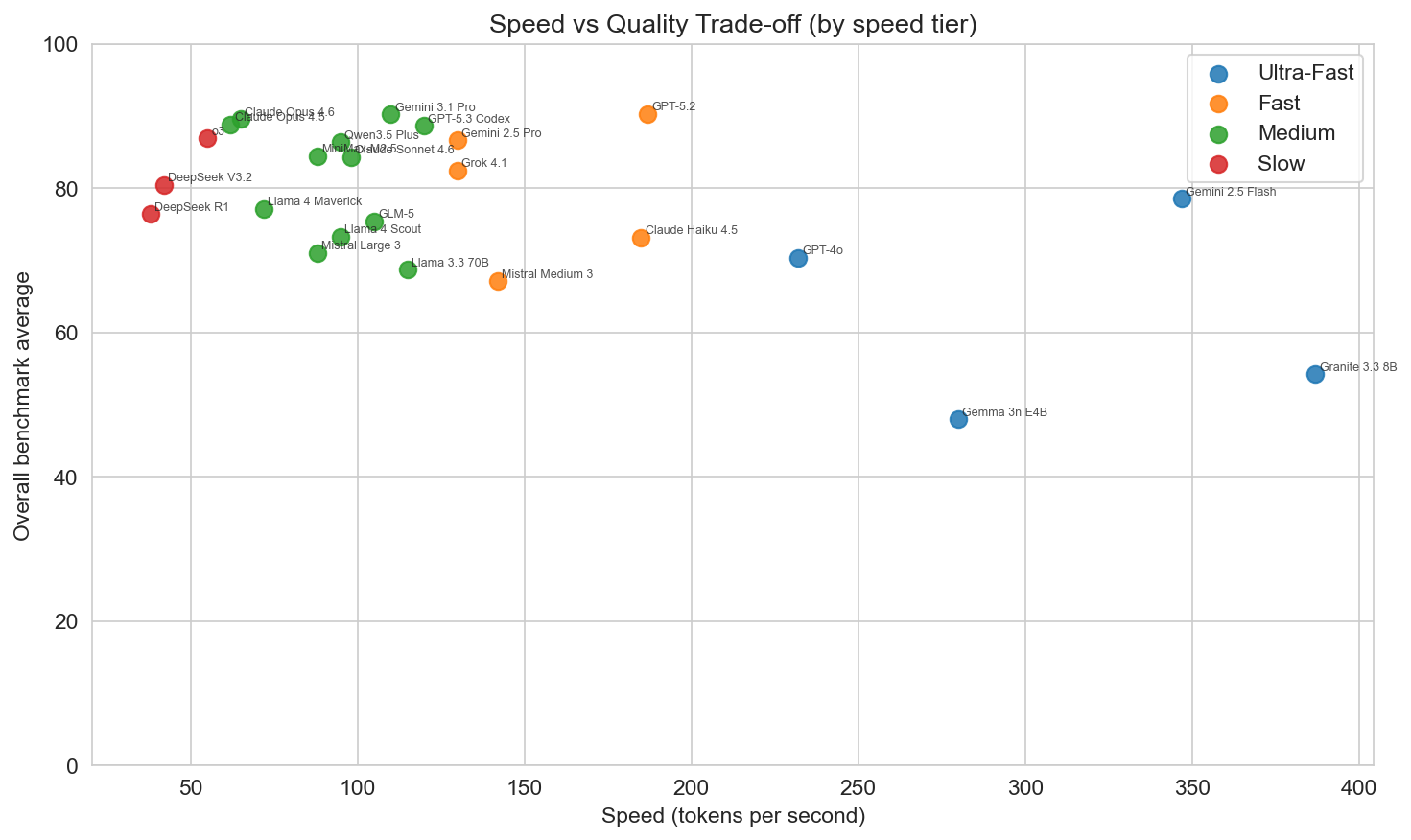
So there is a clear speed–quality trade-off: if you need the highest scores, you give up some speed; if you need the lowest latency and highest throughput, you choose a smaller or flash-tier model and accept a lower benchmark average.
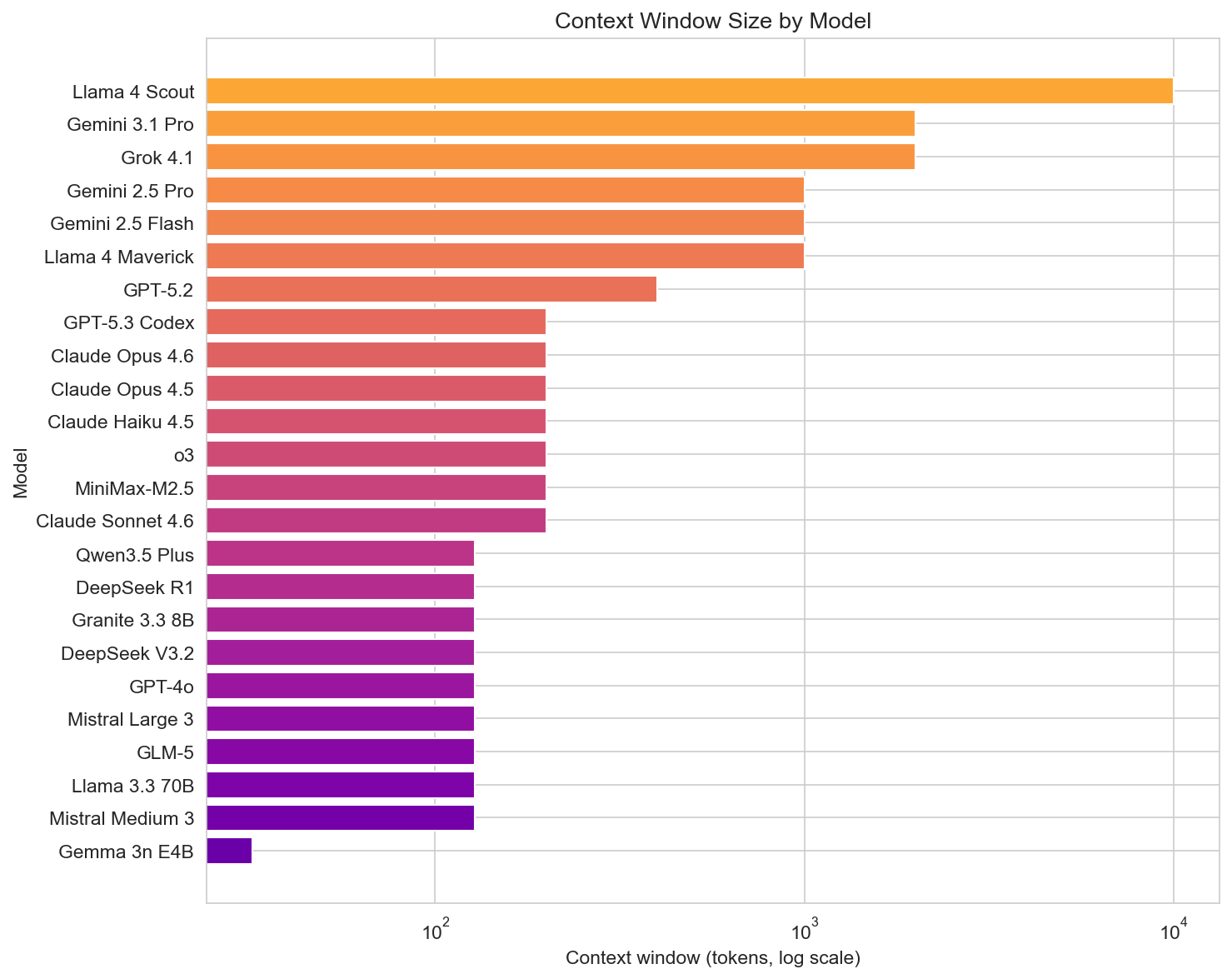
Context and scale
Context window sizes in the dataset range from 32k (Gemma 3n E4B) to 10M (Llama 4 Scout). Extended (128–200k) and large (400k–1M) are common; massive (1M–2M or 10M) is available from Gemini 3.1 Pro (2M), Grok 4.1 (2M), and Llama 4 Scout (10M). Long context is useful for RAG, document QA, and codebases; it often comes with higher cost or slower inference. Models like Gemini 3.1 Pro and Grok 4.1 combine large context with strong benchmarks; Llama 4 Scout offers the largest context in the set for self-hosted or free use.
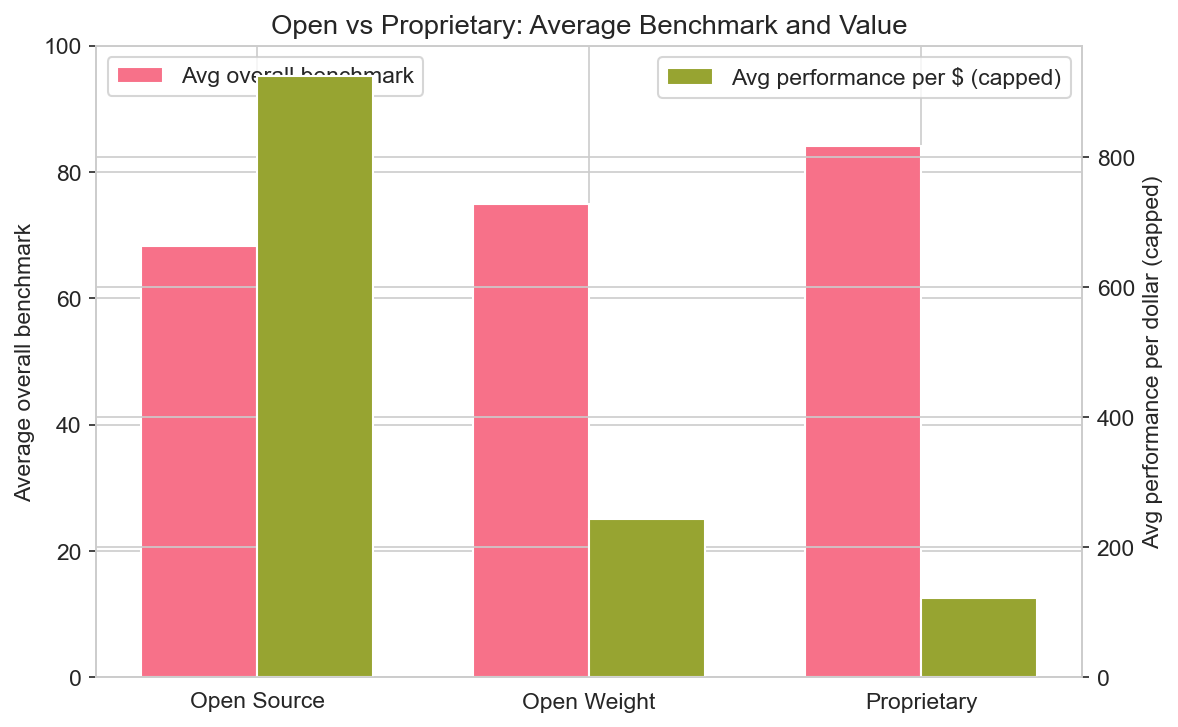
Open vs proprietary
The dataset labels models as Proprietary, Open Source, or Open Weight. In this sample, 13 are proprietary, 7 open source, and 4 open weight. On average, proprietary models have the highest overall benchmark average (84.2), followed by open weight (75.0) and open source (68.3). So the performance gap between closed and open is still visible, but open-weight and open-source models are competitive for many tasks.
Notable open or open-weight models: Qwen3.5 Plus (open weight, strong coding and value), DeepSeek V3.2 and R1 (open source, strong value and coding; R1 is reasoning), Llama 4 Maverick and Scout (open source, free, large context), Mistral Large 3 and Medium 3 (open weight, EU-friendly), GLM-5 (open weight, bilingual). If you need on-prem, compliance, or minimal API cost, the open stack is viable; if you need the absolute top on every benchmark, proprietary still leads.
Who builds what
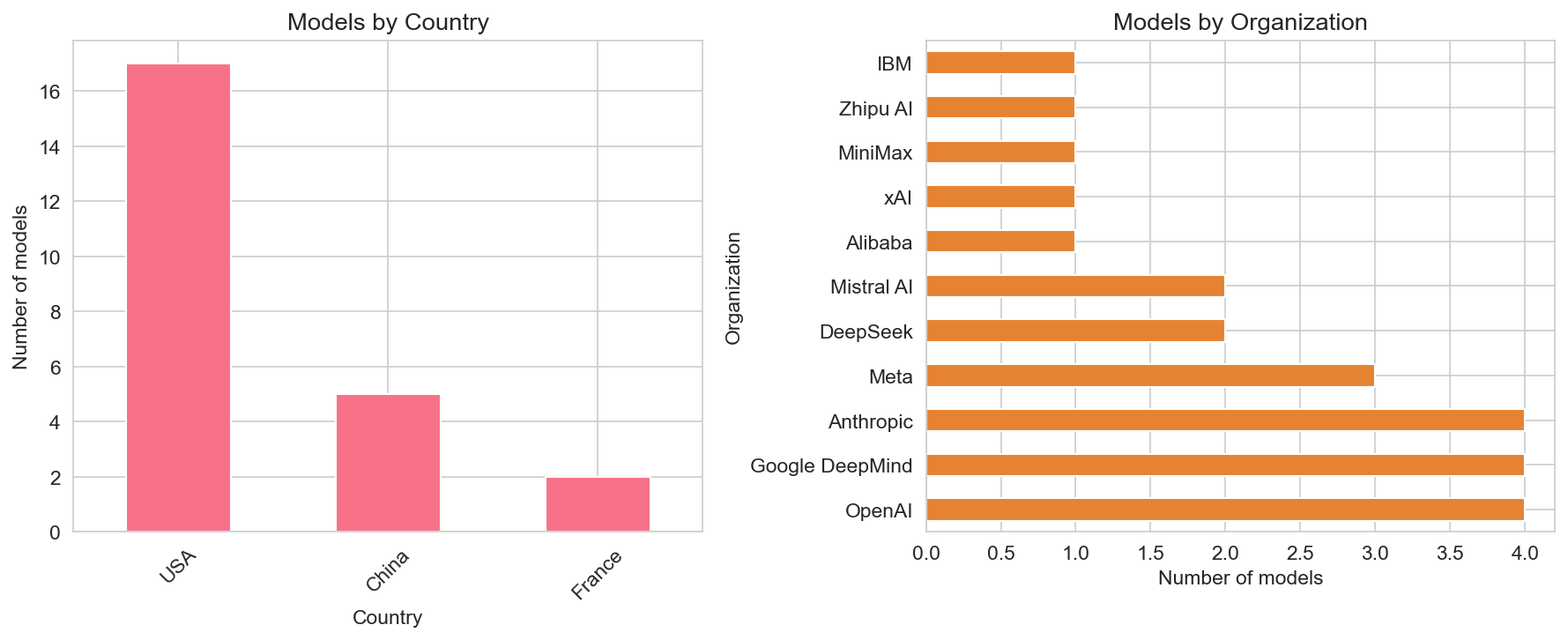
Geography: USA accounts for 17 of the 24 models, China for 5, and France for 2. So the leaderboard is still US-heavy, with strong Chinese representation (Alibaba, DeepSeek, MiniMax, Zhipu) and European presence (Mistral).
Organizations: OpenAI, Google DeepMind, Anthropic, Meta, and xAI each have multiple entries; DeepSeek, Alibaba, Mistral AI, MiniMax, Zhipu AI, and IBM appear with one or two. The top ranks are dominated by a small set of well-funded labs; the long tail is a mix of open-source (Meta, IBM, DeepSeek) and regional or vertical players.
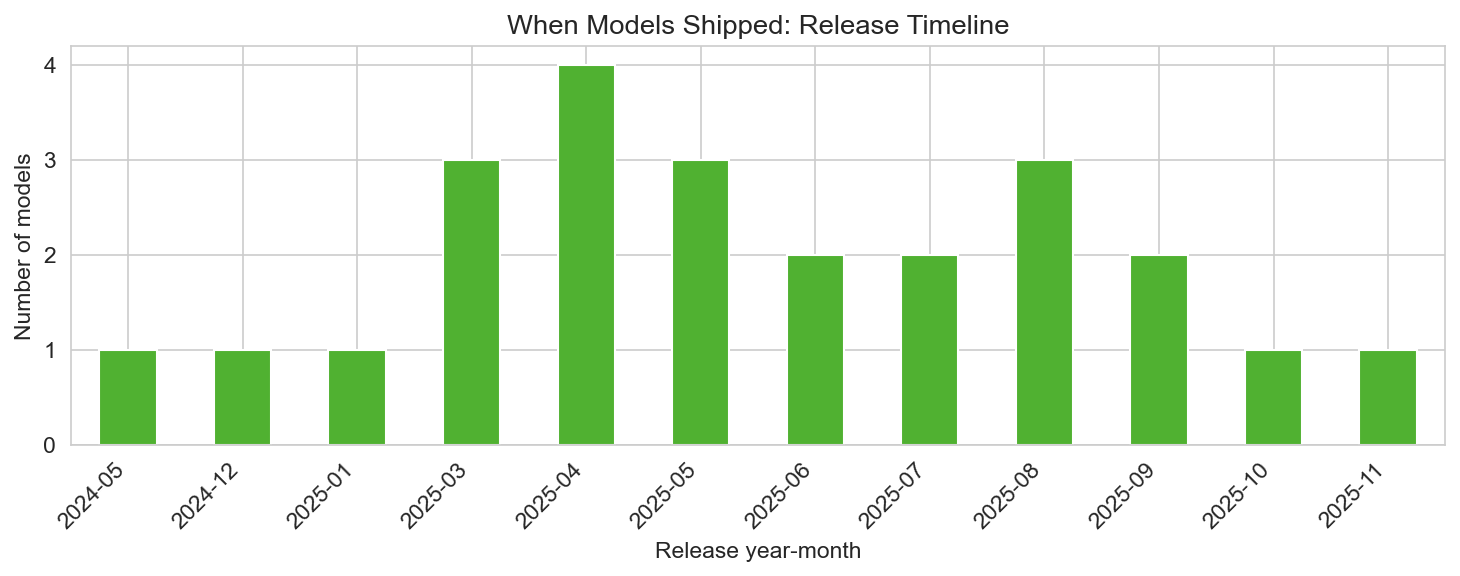
When models shipped
Most models in the set were released in 2025, with a few from 2024 (e.g. GPT-4o, Llama 3.3 70B). Release activity is spread across the year: Q1–Q4 2025 all have multiple launches. That reflects the current pace of the “benchmark wars”: new versions and new entrants appear every few months, so any snapshot is a point in time and rankings can shift with the next release.
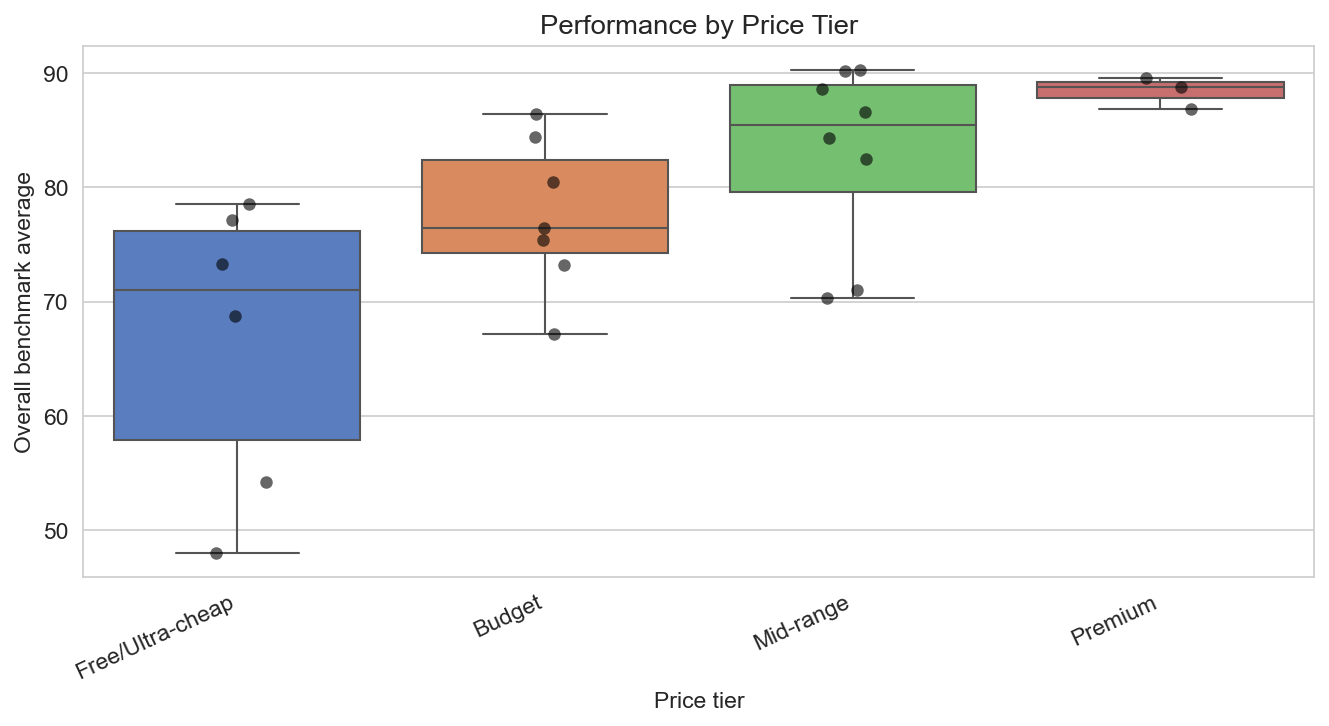
Price tier and performance
Grouping by price tier (Free/Ultra-cheap, Budget, Mid-range, Premium) shows that average performance rises with price tier: free and budget models have lower mean benchmark scores; mid-range and premium models have higher ones. There is overlap—some budget models (e.g. Qwen3.5 Plus, DeepSeek V3.2) score well—but in aggregate you pay more for higher scores. Free and ultra-cheap tiers are ideal for experimentation and high-volume, cost-sensitive use; premium tiers are for maximum capability when cost is secondary.
Choosing a model
- Coding and software engineering: GPT-5.3 Codex, Claude Opus 4.5/4.6, Qwen3.5 Plus, and DeepSeek R1/V3.2 lead on HumanEval and SWE-bench; Codex and Claude lead SWE-bench in this set.
- Complex reasoning and math: o3 and GPT-5.2 lead on reasoning and AIME; use when you need deep chain-of-thought.
- Long context and multimodal: Gemini 3.1 Pro (2M context, GPQA leader), Claude Opus, Grok 4.1 (2M), Llama 4 Scout (10M).
- Budget and value: DeepSeek V3.2, Qwen3.5 Plus, Gemini 2.5 Flash, MiniMax-M2.5, GLM-5; free options include Llama 4 and Llama 3.3 70B.
- Speed and real-time: Gemini 2.5 Flash, Granite 3.3 8B, GPT-4o, Claude Haiku 4.5.
- Open-source / on-prem: Llama 4 Maverick/Scout, DeepSeek R1/V3.2, Mistral Large 3, Qwen3.5 Plus, Gemma 3n E4B, Granite 3.3 8B.
No single model wins every dimension; the right choice depends on whether you optimize for peak performance, cost, speed, context, or licensing.
Conclusion
The LLM benchmark wars in 2025–2026, as captured by this 24-model comparison, show a tight race at the top (GPT-5.2, Gemini 3.1 Pro, Claude Opus), clear benchmark specialists (Codex for code, Gemini for GPQA, GPT-5.2 for MMLU and AIME), and a growing open and value segment (DeepSeek, Qwen, Llama, Mistral). Performance per dollar favors free and low-cost models; raw performance favors premium APIs. Speed, context length, and modality add more dimensions to the trade-off. Using data like this to align model choice with your priorities—benchmarks, cost, speed, and openness—makes the landscape easier to navigate.
Data and methodology
The analysis is based on the LLM Benchmark Wars 2025–2026 | 24 Models Compared dataset (Kaggle: alitaqishah/llm-benchmark-wars-2025-2026-24-models-compared). The CSV includes 24 models with fields for rank, model name, organization, country, release year/month, type (Proprietary / Open Source / Open Weight), architecture, modality, open_source flag, parameters (B), context window (k), input/output price per 1M tokens (USD), six benchmark scores (MMLU, HumanEval, GPQA Diamond, SWE-bench, HellaSwag, AIME 2025), overall benchmark average, performance per dollar, speed (tokens/s), latency (s), reasoning_model and multimodal flags, best_for, license, and tier labels (speed, price, context). Figures were generated with pandas and seaborn from this CSV; no rows were excluded. All benchmark and price values are as in the source dataset. The dataset author is alitaqishah on Kaggle; we thank them for the compilation and recommend the source for updates and full details.



